Over the course of my first two weeks at the Recurse Center I’ve found myself in a rabbit hole of working with geospatial data. More specifically, I’ve collected a pretty sizable dataset on my personal location history using a small Swift app that pings my home server with my current whereabouts, which then stores it in a PostGIS database. Given that I’m currently teaching myself about data science/visualization, this seemed like the perfect starting point to practice gaining insights from a set of data.
Pretty early on I realized that the location data I was collecting was certainly interesting, however there was only so much you could do with a bunch of location coordinates and timestamps:
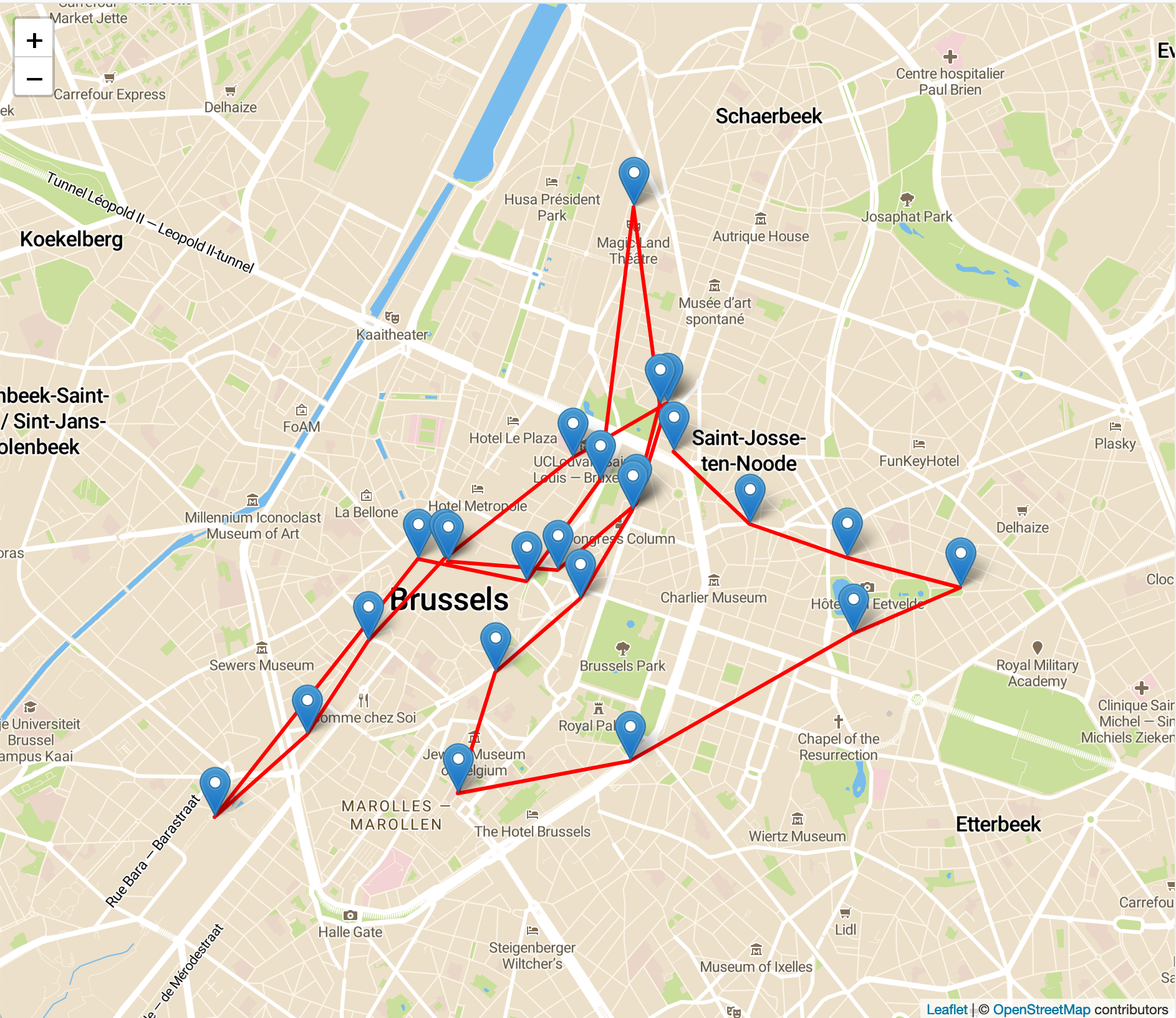
A day walking around Brussels. Interesting in itself, but we can do even more!
In order to dive into more interesting insights about where I’ve been spending my time, I wanted to add city and neighborhood information to each of these coordinates. A naive way to handle this situation is to use something like Google’s reverse geocoding API, but I have a personal grudge against Google’s mapping monopoly and also wanted to get my hands a bit dirty, so instead opted to use Open Street Maps. There didn’t appear to be a ton of documentation on how to do something like this, so I hope this guide is helpful to anyone trudging down a similar path in the future!
Note: The remainder of this guide assumes you have a Postgres installation with the PostGIS extension installed, a database created, and the extension enabled:
CREATE EXTENSION postgis;
If you’re looking for a shortcut you can also use a PostGIS Docker image like this one.
Importing OSM Data
The first step in my journey was getting OSM data into my Postgres database. If you take a peek at the planetary OSM dumps, you’ll be quickly discouraged by an enormous 77GB file. Though I do love traveling, I haven’t quite made it to all 77GB of Earth just yet, so this dataset wouldn’t do. Luckily a quick google search reveals a variety of community members who release smaller subsets of the OSM map; I ended up with Geofabrik’s regional dumps, which are updated daily. Most of my location data is within New York so the NY state dump was sufficient to start out with.
Downloading the dump will leave you with a mysterious .osm.pbf file, which contains information like streets, buildings, points of interest, and everything else necessary to render a map of the selected region. Most importantly, this file also contains data on places, which provide us with cities, villages, boroughs, neighborhoods etc. This is what we’ll need to make our reverse geocoder.
Getting this data into our Postgres db isn’t actually too hard thanks to osm2pgsql. It’ll handle all of the details of converting our dump into a nice relational model that can be thrown into our Postgres database. Running it is pretty straightforward:
osm2pgsql \
-U postgres \
-H 127.0.0.1 \
-d my-database-name \
~/Downloads/new-york-latest.osm.pbf
Give it a few minutes to do its thing and you’ll be left with a few new tables in your database, the most relevant of which are:
planet_osm_point– This table contains our neighborhoods, cities, etc. but specifies them based on a single point.planet_osm_polygon– This table contains similar data toplanet_osm_point, but defines them by a shape (ie a polygon) rather than a singular point.
We’ll jump back to these two tables in a little bit…
Joining data
Now that we have our OSM data loaded into PG we can get to the fun part: reverse geocoding!
In my particular case, I had a table of locations with the following schema:
CREATE TABLE locations (
id SERIAL PRIMARY KEY,
point geometry(Point,4326) NOT NULL,
created_at timestamp without time zone NOT NULL,
altitude numeric,
hacc numeric,
vacc numeric,
speed numeric,
course numeric
);
This is mostly straightforward, however there are a few gotchas that you should be aware of regarding the point field. For starters, note that this field is of type geometry, not geography. The OSM data that we’ve imported uses geometry in its schema, so I’d recommend conforming just to avoid a translation step when you want to join the two datasets. If you’re wondering what the difference between the two is, check out this StackOverflow question.
Also notable is the 4326 in the point’s type definition. This magical-looking number is actually a Spatial Reference System identifier and corresponds to the projection that is being used for the coordinates in the database. Since I’m collecting data from iOS, my schema needs to use the WGS 84 projection (as mentioned by the CLLocationCoordinate2D reference). You may need to change this depending on where you’re getting your location data from, so keep this in mind.
Another subtle but major gotcha that should be mentioned is the ordering of coordinates while inserting data. The order is lon, lat not lat, lon! An example:
-- Note that NYC's lat/lon is 40.730610, -73.935242.
-- This is wrong!!
INSERT INTO locations (point) VALUES (POINT(40.730610 -73.935242))
-- This is right :)
INSERT INTO locations (point) VALUES (POINT (-73.935242 40.730610))
As stupid as this looks, it had me stuck for longer than I’d care to admit. Learn from my mistakes! While us normies usually use lat, lon, “the biz” has standardized around the reverse ordering.
Spatial joins
At this point we’ve imported some OSM data into our database and hopefully have some example points in some table locations. The next step is to come up with a magical query to unite these two datasets, resulting in a nice dataset of location points and their associated city and neighborhood.
Drumroll please 🥁…
SELECT
locations.created_at AS timestamp,
neighborhoods.name AS neighborhood_name,
cities.name AS city
FROM
locations
CROSS JOIN LATERAL (
SELECT
planet_osm_point.name,
planet_osm_point.way
FROM
planet_osm_point
WHERE planet_osm_point.place = 'neighbourhood'
ORDER BY
ST_Transform(locations.point, 3857) <-> planet_osm_point.way
LIMIT 1
) AS neighborhoods
LEFT OUTER JOIN planet_osm_polygon cities ON
ST_Contains(cities.way, ST_Transform(locations.point, 3857)) AND
cities.place = 'city'
ORDER BY timestamp DESC
If all goes well, you’ll be given with a result like this:
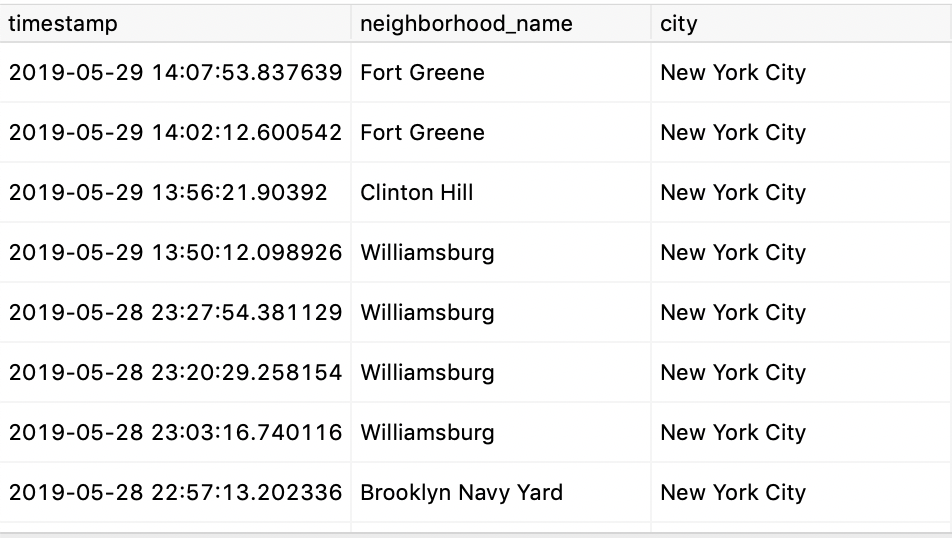
Pretty cool, right?
That query was a bit scary looking, so let’s split it up a bit to make things a bit easier to grok:
SELECT
locations.created_at AS timestamp,
neighborhoods.name AS neighborhood_name,
cities.name AS city
FROM
locations
This chunk is specifying the columns that we’re going to be selecting. The created_at field from the locations table is straightforward, but what about these neighborhoods and cities tables? These are artificial tables which we’ll construct in the next two chunks (our joins).
CROSS JOIN LATERAL (
SELECT
planet_osm_point.name,
planet_osm_point.way
FROM
planet_osm_point
WHERE planet_osm_point.place = 'neighbourhood'
ORDER BY
ST_Transform(locations.point, 3857) <-> planet_osm_point.way
LIMIT 1
) AS neighborhoods
This chunk is how we’re determining a point’s neighborhood. We’re using a CROSS JOIN LATERAL because we’ll need to run the statement to the right of the LATERAL for each row in our result (probably not the most performant, but hey, it’ll do for this demo).
You’ll notice that this subquery is using the planet_osm_point table rather than planet_osm_polygon. In theory we should be able to determine the neighborhood by querying they polygon database to see in which neighborhood the point resides (using the ST_Contains) function. Unfortunately I found that this didn’t work quite as well as I’d hoped in practice. In my testing, I found that the OSM data dump for New York didn’t seem to have many neighborhoods in Brooklyn defined as polygons, so I’d see quite a few NULL responses.
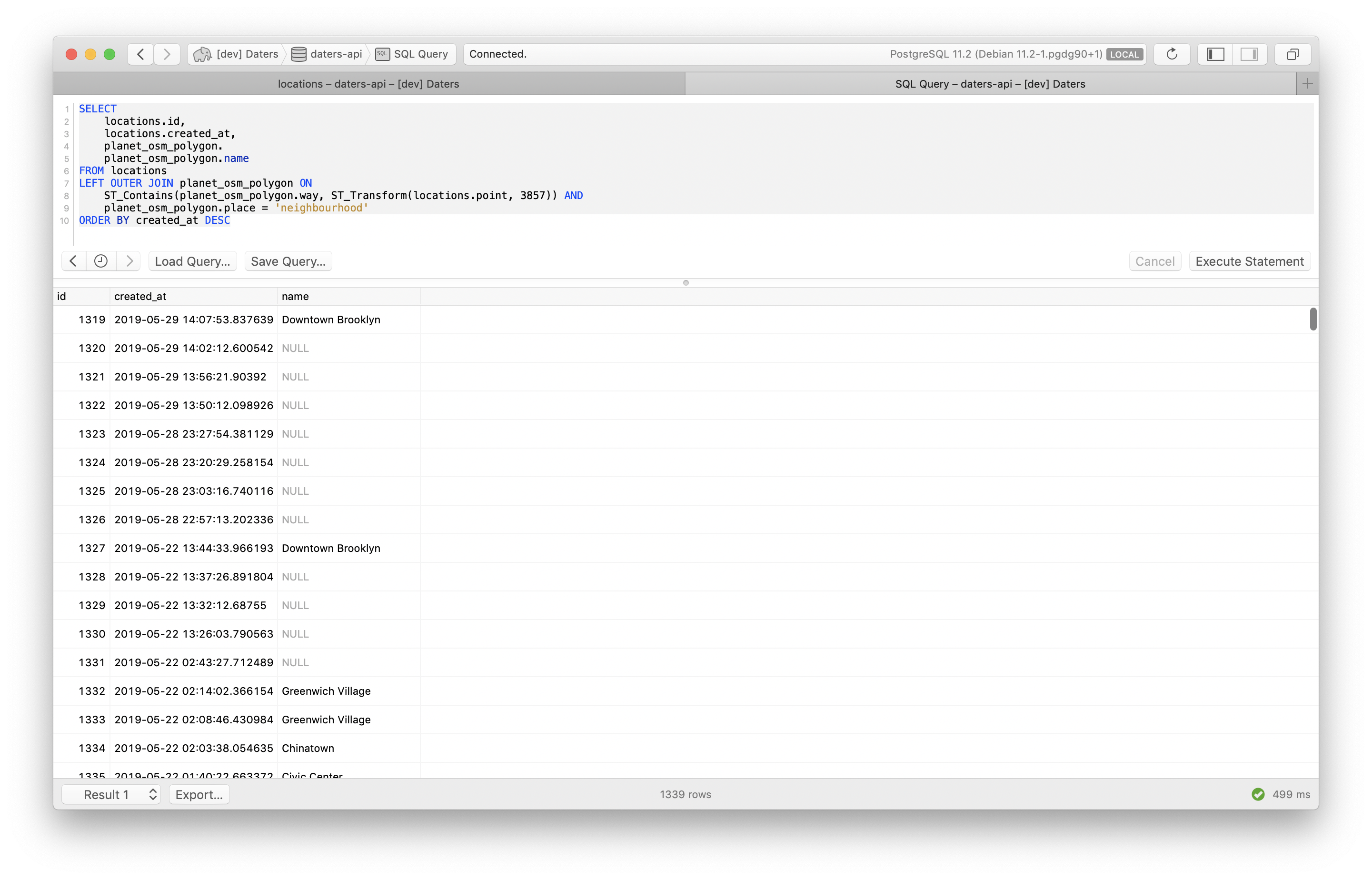
Instead I opted for the next best solution I could think of, which was determining the neighborhood by performing a nearest neighbor search. The best way to think about this is in terms of a Voronoi diagram:

In our case, the dots would be the neighborhood epicenters, defined by planet_osm_point, and the colored areas would represent the boundaries of neighborhoods. When we run the above CROSS JOIN query, we’re finding the closest neighborhood epicenter to our location and returning it. It’s not the most accurate solution, but based on a manual review of the dataset it seems to be good enough for my purposes.
Also note the ST_Transform(locations.point, 3857) in our ORDER clause. Remember the spatial reference identifier (SRID) mentioned earlier? It rears its head once more while trying to query data, as OSM’s dataset is encoded with an SRID of 3857 while Apple Maps uses 4326. In order for our query to work we’ll need to transform our location table’s data into OSM’s projection using the ST_Transform function. Thankfully PostGIS makes this easy for us!
Phew, okay, let’s move onto the next chunk of our query which is quite a bit simpler:
LEFT OUTER JOIN planet_osm_polygon cities ON
ST_Contains(cities.way, ST_Transform(locations.point, 3857)) AND
cities.place = 'city'
Luckily for us, cities appear to be reliably defined as polygons in planet_osm_polygon, allowing us to greatly simplify our query and be more confident in its results. In this case, we’re using the ST_Contains function of PostGIS to determine which city our point resides within.
Putting each of these query chunks together, we get our resulting neighborhood and city data 🎉.
Voilà
There you have it! We’ve created our own rough version of a reverse geocoder using open source tools and data. Feels good, right?
Keep in mind that this was my first foray into geospatial databases, therefore there are quite a few improvements that could be made over this approach. A few ideas:
- Filter out unneeded data from the OSM dumps before importing. We don’t need point of interest, roads, subway stops, etc. for this particular use case. Using a tool like osmfilter to distill the dataset down to country/city/neighborhood boundaries only would make importing the entire planet (rather than just a region) much more practical.
- Get better neighborhood boundaries. Perhaps I’m missing something, but the lack of reliable polygon definitions of NYC neighborhoods is less than ideal. Sourcing more reliable data would help improve the quality of results. As a side tangent, I want to overlay a Voronoi diagram over a real NYC neighborhood map just to see how inaccurate this method is.
- Optimize. As mentioned, the
CROSS JOIN LATERALis pretty inefficient, requiring a subquery to be run for each row. With a dataset of ~1300 location points this query ends up taking around 12s on a 2.9GHz Intel i5. For larger datasets it’d be great to have a more efficient query.
Hopefully this guide was helpful, but if you have any further questions feel free to reach out to me via email or Twitter.